Undermining the integrity of an office prediction contest
(22 Oct 2018) This short write-up was posted directly on Github two days before the 2018 World Cup final. It’s not a very serious bit of analysis, but I am still proud of our marital teamwork.
My wife entered a World Cup prediction contest at her workplace. Every day of the tournament, the participants predict the exact score of a selected game, and those who guessed right split the day’s jackpot. Predicting exact scores is a mug’s game, but sending my wife back with detailed arguments in favour of a proper Asian Handicap setup would have aroused suspicions.
The group stage
I had 3 hours notice to submit the 16 predictions for the group stages, so I
did a crude copy & paste job of a pure Dixon-Coles model
from @Torvaney’s excellent
blogpost.
To run it, open and run groups.R in RStudio, then call predict(...) to get
the probability mass for all scores from 0:0 to 3:3. I picked the likeliest
score for every game as our prediction.
The knockout stage
For the knockout stages I had a little more time, but I spent it reimplementing Dixon-Coles in Stan. The one departure from pure Dixon-Coles is counting the World Cup games thrice in the model, ensuring that they influence the model much more than pre-WC games. It’s hacky, but I don’t care really. Speaking of hacky, the model has the following drawbacks:
- No information beyond the scores is used (so no shots, xG, etc.) This has led the model to overestimate Belgium quite a bit.
- Apart from the WC games hack, all games weigh equally in the model – the last qualification game is as important as a friendly a year ago.
- The home field advantage factor is the same for friendlies and qualifiers and the World Cup proper. This means that the model underestimated Russia somewhat.
- As noted by @Torvaney in the original post, there is insufficient information for the ratings to work with the same accuracy across confederations as they do within, which is a problem especially for the group stages.
To run the Stan model, it is best to open an IPython console and say:
%run knockouts.py
data, team_map = wrangle()
samples = fit(data, chains=7, iter=4000) # 7 chains * 2k steps = 14k samples
predict(samples, team_map, "France", "Croatia", neutral=True, aet=True)
which displays the prediction for the final on Sunday:
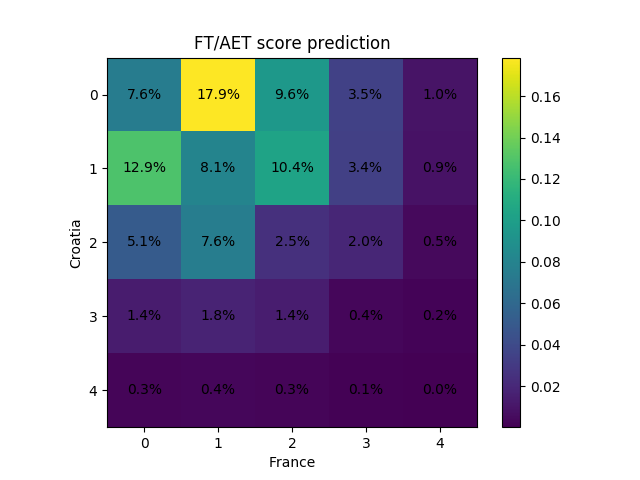
Over the course of the contest our predictions have often been 0-0 and 1-0, with precious few 2-1s. This follows from the low-scoring nature of football, but when put together in a list it looks strange. Still, the system works. So far, we have got Spain 1-0 Iran, France 0-0 Denmark, Colombia 1-0 Senegal and Sweden 1-0 Switzerland correct, placing us a joint second with the total winnings of CHF 90 (that is CHF 40 net, as the entry fee was CHF 50.) Not bad, even if three of these were saved by VAR; on the other hand, we came painfully close with Brazil 1-0 Mexico, France 1-0 Uruguay and Russia 1-2 Croatia.